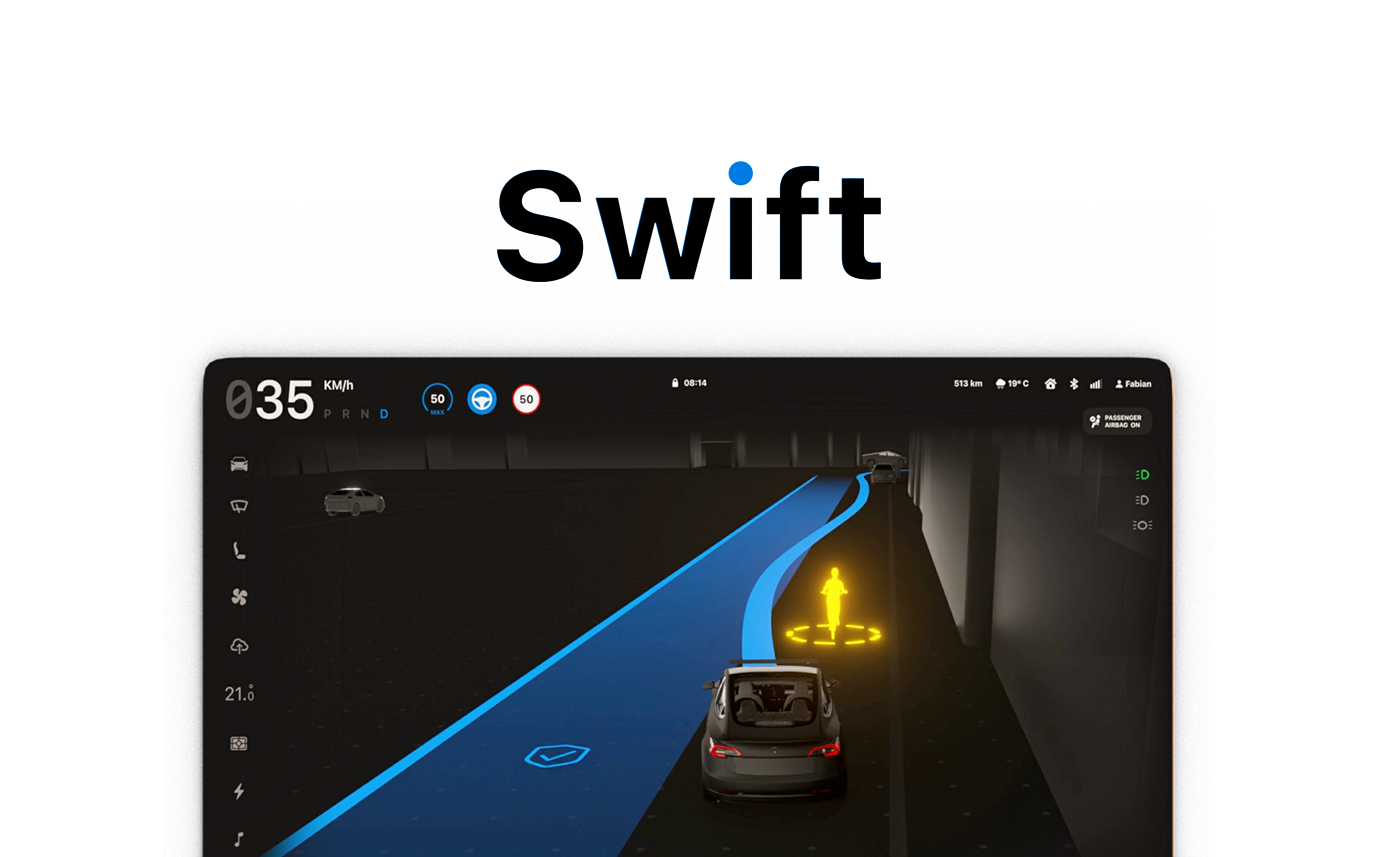
StudiengangInteraktionsgestaltung B.A. Digital Product Design and Development Interaktionsgestaltung Kommunikationsgestaltung Produktgestaltung Sichtbar – Jüdische Biogr … Digitale ExponateIG4, KG4, IOT4 (Wi 2021/22) Gier in Märchen – Interak … Digitale ExponateIG4, KG4, IOT4 (So 2021) viewport - Politik im öff … Lean Design ProjectIG6, IOT6, IOTA6 (So 2021) Swift - Adaptives Dashboa … Bachelorarbeiten InteraktionsgestaltungIG7 (So 2021) Google Replica Invention Design 1IG3 (So 2021) miiim – Das Meme-Lexikon WebIG4, KG4, KG6 (So 2021) Verschwörungstheorien: Zw … Digitale ExponateIG4, KG4, IOT4 (So 2021) TrackMag - Prevent Food W … Invention Design 1IG3 (Wi 2020/21) ESID Bachelorarbeiten InteraktionsgestaltungIG7 (Wi 2020/21) Jobspace Lean Design ProjectIG6, IOT6 (Wi 2021/22) Lexia - Interactive Train … Invention Design 2IG4 (So 2020) itery Interface Design 1IG2 (Wi 2021/22) SonoAID - eine Alltagshil … Invention Design 2IG4, IOT4 (Wi 2021/22) tapin Invention Design 1IG3 (So 2022) Velo. think bike Lean Design ProjectIG6, IOT6 (Wi 2021/22) adapt – Eine Anwendung fü … Bachelorarbeiten InteraktionsgestaltungIG7 (So 2022) Gestalterische Interventi … Bachelorarbeiten InteraktionsgestaltungIG7 (So 2022) Giftiges Europa Digitale ExponateIG4, KG4, IOT4 (So 2022) AirMouse Interface Design 1IG2 (So 2022) TruckMate Interface Design 2IG4, IOT4 (Wi 2022/23) CuraVent Interface Design 2IG4 (So 2022) bridge Lean Design ProjectIG6, IOT6 (Wi 2022/23) Datakulli & Datapette Interface Design 1IG2 (Wi 2022/23) Kugelblitz Lean Design ProjectIG6, IOT6 (Wi 2022/23) RepAiR - AR Reparaturhilf … Invention Design 1 + 2IG3 (Wi 2022/23) AccessAbility Interface Design 2IG4, IOT4 (So 2023) Ausstellungskonzept zur M … Bachelorarbeiten InterdisziplinärIG7, IOT7, KG7, PG7 (So 2023) DETACT Invention Design 1 + 2IG3 (Wi 2022/23) five. Bachelorarbeiten InterdisziplinärIG7, IOT7, KG7, PG7 (Wi 2022/23) WayMate Bachelorarbeiten InteraktionsgestaltungIG7 (So 2023) impatiens glandulifera Digitale ExponateIG4, KG4, IOT4 (So 2023) Noto Invention Design 2IG4, IOT4 (So 2023) ErsteHilfe + Invention Design 1IG3 (So 2023) pad-e Interface Design 2IG4, IOT4 (Wi 2022/23) Ora - Ein ganzheitliches … Bachelorarbeiten InteraktionsgestaltungIG7 (Wi 2023/24) indi: Kompressionsstrumpf … Bachelorarbeiten InterdisziplinärIG7, IOT7, KG7, PG7 (Wi 2023/24) ZYKLUSSTOP Bachelorarbeiten InterdisziplinärIG7, IOT7, KG7, PG7 (Wi 2023/24) Mia – Intelligenter Assis … Lean Design ProjectIG6, IOT6 (Wi 2023/24) Lou — A parking assistant Interface Design 2IG4 (Wi 2023/24) PhAI - A departure from d … Bachelorarbeiten InteraktionsgestaltungIG7 (Wi 2023/24) cosmo - discover the colo … Bachelorarbeiten InteraktionsgestaltungIG7 (Wi 2023/24) The Seabed Interaktive Kommunikationssysteme 1IG2 (Wi 2023/24) habitat Bachelorarbeiten InteraktionsgestaltungIG7 (Wi 2021/22) The Haptic Fragment Bachelorarbeiten InteraktionsgestaltungIG7 (So 2020) Walli's Welt Bachelorarbeiten InteraktionsgestaltungIG7 (Wi 2020/21) acce Interface Design 2IG4 (So 2021) ConRad - Fahrrad-Sharing … Interface Design 2IG4 (So 2021) Münsterbau Digitale ExponateIG4, KG4, IOT4 (Wi 2021/22) Ran.Seq Interface Design 1IG2 (So 2022) DeepSea Programmiertes Entwerfen 1IG1 (So 2023) PACIAN Bachelorarbeiten InteraktionsgestaltungIG7 (So 2017) MH1 - Intuitiv über Dista … Invention Design 1IG3 (So 2015) Myogram, device - übergre … Bachelorarbeiten InteraktionsgestaltungIG7 (Wi 2017/18) Avaos - Konzept eines mod … Bachelorarbeiten InteraktionsgestaltungIG7 (Wi 2010/11) beam Bachelorarbeiten InteraktionsgestaltungIG7 (So 2018) Diamate - Dein persönlich … Bachelorarbeiten InteraktionsgestaltungIG7 (Wi 2015/16) Raising Robotic Natives Lean Design ProjectIG6 (Wi 2015/16) FX:Mone Bachelorarbeiten InteraktionsgestaltungIG7 (So 2016) Hint – System zur Steueru … Bachelorarbeiten InteraktionsgestaltungIG7 (Wi 2016/17) Feet: eine Studie zu fußb … Invention Design 1IG3 (Wi 2014/15) Stadtplanung Bachelorarbeiten InteraktionsgestaltungIG7 (Wi 2010/11) CCU Monitor Lean Design ProjectIG6 (Wi 2015/16) Stiftlabor Lean Design ProjectIG6 (So 2010) Informative Frischetheke … Bachelorarbeiten InteraktionsgestaltungIG7 (Wi 2011/12) Location-Based Light Pain … Ausstellung und Interaktive KommunikationssystemeIG4, KG4 (So 2014) Superintelligence Control … Bachelorarbeiten InteraktionsgestaltungIG7 (So 2016) Adonis Invention Design 2IG4 (Wi 2019/20) hybmix - digitales mischp … Bachelorarbeiten InteraktionsgestaltungIG7 (So 2014) Stift+Interaktion Bachelorarbeiten InteraktionsgestaltungIG7 (Wi 2010/11) Vernetze Brandmelder Lean Design ProjectIG6 (So 2015) In My Fridge Lean Design ProjectIG6 (So 2011) Xtend Interface Design 1IG2 (Wi 2023/24)